

KEYNOTE: เปิดประตูสู่ AI Workloads ที่ล้ำสมัยด้วย OpenStack และ GPUs
Published : November 15, 2024
Time : 5 min read
การพัฒนาระบบโมเดลภาษาใหญ่ (LLM) บนระบบคลาวด์กำลังเป็นกระแสสำคัญในวงการเทคโนโลยี โดยเฉพาะเมื่อต้องประมวลผลข้อมูลมหาศาล เช่น การจัดการข้อมูลเรซูเม่จำนวนกว่า 2 ล้านฉบับต่อเดือน ทว่าการนำ LLM มาปรับใช้กับงานระดับนี้ยังคงเผชิญความท้าทายในด้านต้นทุน ความแม่นยำ และเวลาในการประมวลผล
งาน OpenInfra Summit Asia 24 ที่ผ่านมา NIPA Cloud ได้นำเสนอวิธีการเลือกระบบ LLM และแนวทางการปรับแต่งเพื่อให้เหมาะสมกับความต้องการและงบประมาณ
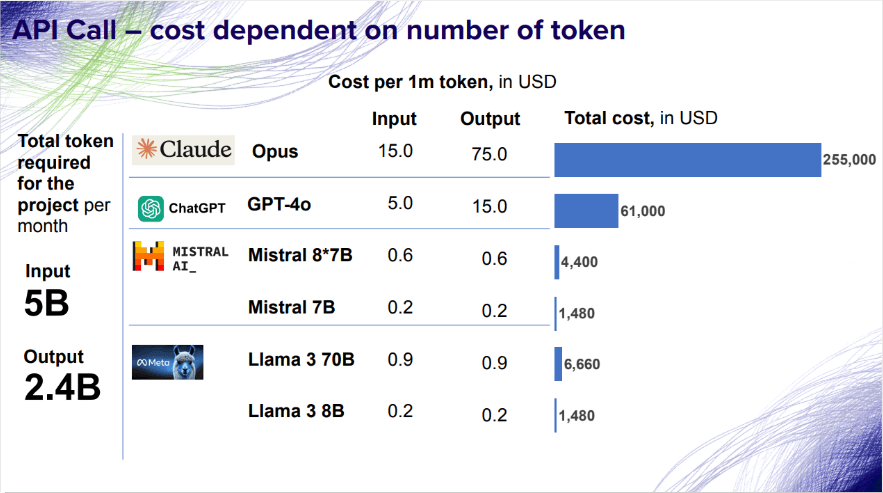
ความสำคัญของการออกแบบระบบ LLM ที่เหมาะสม
การเลือกใช้งาน LLM ในระบบคลาวด์ต้องพิจารณา 3 ปัจจัยหลัก ได้แก่
ต้นทุน การใช้บริการ API โมเดลแบบปิด เช่น ChatGPT หรือ Claude ซึ่งมีค่าใช้จ่ายสูงถึง 61,000 ถึง 255,000 ดอลลาร์สหรัฐต่อเดือน ในขณะที่การใช้โมเดลโอเพนซอร์ส เช่น Mistral หรือ Llama มีต้นทุนอยู่ที่เพียง 1,500 ถึง 6,500 ดอลลาร์สหรัฐต่อเดือน
ความแม่นยำ ผลการทดสอบแสดงว่า Mistral ขนาดใหญ่มีความแม่นยำสูงสุดถึง 87.5% เทียบกับ Llama ขนาดใหญ่ที่ 82.6%
เวลาในการประมวลผล (Latency) ระบบ API เช่น Groq มีเวลาแฝงต่ำเพียง 3 วินาที ในขณะที่การประมวลผลด้วย GPU รุ่น Nvidia A10 อาจใช้เวลา 25 วินาที
สำหรับองค์กรที่ต้องการลดต้นทุนและเพิ่มประสิทธิภาพ การเลือกใช้โมเดลเปิดและการปรับแต่งด้วยวิธีต่าง ๆ เช่น การลดขนาดโมเดล (Quantization) หรือการโฮสต์โมเดลเอง (Self-hosting) ถือเป็นทางเลือกที่คุ้มค่า
การตัดสินใจระหว่างการใช้ API และการโฮสต์เอง
1. การใช้ API การใช้บริการ API เช่น Bedrock, Together.ai และ Groq เป็นตัวเลือกที่ง่ายและรวดเร็ว แต่มีข้อจำกัดด้านต้นทุนและการปรับแต่ง ตัวอย่างเช่น Bedrock มีค่าใช้จ่ายประมาณ 4,200 ดอลลาร์ต่อเดือน และมีเวลาแฝงเฉลี่ย 17 วินาที
2. การโฮสต์ LLM ด้วยตนเอง การโฮสต์ LLM ด้วยตนเองช่วยลดค่าใช้จ่ายได้มาก โดยเฉพาะเมื่อใช้เทคนิคอย่างการปรับลดขนาดโมเดล (Quantization) ตัวอย่างคือ Nvidia A4000 ซึ่งรองรับโมเดลขนาดเล็กในต้นทุนเพียง 850 ดอลลาร์

การเลือก GPU และการปรับแต่งฮาร์ดแวร์
1. ปัจจัยการเลือกฮาร์ดแวร์ การเลือก GPU ควรพิจารณาความจุหน่วยความจำ (Memory) กำลังการประมวลผล (Compute Power) และแบนด์วิดท์ (Bandwidth) ตัวอย่างเช่น
- Nvidia A100 หน่วยความจำ 80GB เหมาะสำหรับโมเดลขนาดใหญ่ เช่น Mistral Large (46.7 พันล้านพารามิเตอร์)
- Nvidia A10 หน่วยความจำ 24GB เพียงพอสำหรับโมเดลขนาดเล็ก เช่น Mistral Small (7 พันล้านพารามิเตอร์)
2. ลดข้อกำหนดด้วย Quantization การปรับโมเดลให้ใช้บิตน้อยลง เช่น จาก 16 บิตเหลือ 4 บิต ช่วยลดความต้องการหน่วยความจำจาก 16.8GB เป็น 4.2GB สำหรับ Mistral Small
เทคนิคขั้นสูงเพื่อเพิ่มประสิทธิภาพ LLM
1. Speculative Encoding วิธีการนี้ช่วยลดเวลาแฝงได้ถึง 50% เช่น ลดจาก 14.3 วินาทีเหลือเพียง 7.15 วินาที โดยไม่สูญเสียความแม่นยำ
2. การตั้งค่าผ่าน OpenStack การปรับแต่ง OpenStack ด้วย GPU Passthrough ช่วยเพิ่มประสิทธิภาพ เช่น การโหลดโมดูล vfio-pci และการตั้งค่า Nova Scheduler เพื่อสนับสนุน GPU
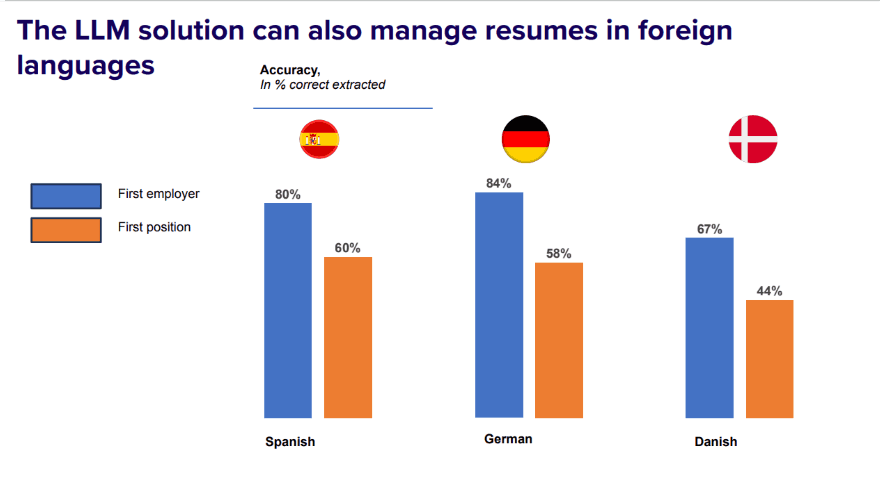
กรณีศึกษา การพัฒนาระบบการจัดการข้อมูลเรซูเม่
การใช้ Mistral LLM ในการประมวลผลเรซูเม่ 2 ล้านฉบับต่อเดือน ช่วยเพิ่มความแม่นยำจาก 44% (วิธีเดิม) เป็น 96% พร้อมรองรับภาษาต่างประเทศ เช่น สเปนและเยอรมัน ด้วยความแม่นยำที่สูงขึ้น
สรุป
การนำ LLM มาใช้งานในระบบคลาวด์จำเป็นต้องการการวางแผนที่รอบคอบ ทั้งการเลือกใช้โมเดลโอเพนซอร์ส การปรับแต่งฮาร์ดแวร์ และการนำเทคนิคขั้นสูง เช่น Quantization และ Speculative Encoding มาใช้ เพื่อให้ได้ระบบที่คุ้มค่าและมีประสิทธิภาพสูงสุดในยุคดิจิทัล และสำหรับผู้ที่มองหาคลาวด์โซลูชันที่ครบวงจร NIPA Cloud พร้อมให้บริการระบบคลาวด์ที่รองรับ GPU เช่นเดียวกัน เพื่อให้ธุรกิจของคุณสามารถก้าวทันโลกแห่ง AI ได้อย่างดียิ่งขึ้น

We—as a team of Thai people—are assured that Thai cloud is the absolute answer for driving your business in the digital era.